NMscanData: Find And Combine All Output And Input Data
Source:vignettes/NMscanData.Rmd
NMscanData.RmdBuilt 2026-07-10 using NMdata 0.2.5.903.
Please make sure to see latest vignette version available here.
Objectives
This vignettes aims at enabling you at
Using NMscanData to read and combine all output and input data based only on (the path to) the Nonmem list file (understanding how NMscanData prioritizes output and input data in case of redundancy)
Switching between combining output and input data by mimicking the Nonmem data filters (IGNORE/ACCEPT) and merging by a row identifier
Configuring
NMdatato return the data class of your preference (saydata.tableortbl) instead ofdata.framewhich is defaultUsing automatically generated meta data to look up information on input and output tables, how they were combined, and results of checks performed by
NMscanData.Including input data rows that were not processed by Nonmem (
ACCEPTandIGNORE)Combining such data sets for multiple models
If available, using an rds file to represent the input data in order to preserve all data properties (e.g. factor levels) from data set preparation
After having checked the rare exceptions, feeling confident that
NMscanDatashould work on all your Nonmem models
Introduction
This vignette focuses on how to use NMdata to automate
what needs to be trivial: get one dataset out of a Nonmem run, combining
all output tables and including additional columns and rows from the
input data. After scanning the Nonmem list file and/or control stream
for file and column names, the data files are read and combined.
In brevity, the most important steps are:
- Based on list file (often
.lst): Identify input and output table files - Read and combine output tables
- If wanted, read input data and restore variables that were not output from the Nonmem model.
- If wanted, also restore rows from input data that were disregarded in Nonmem (e.g. observations or subjects that are not part of the analysis)
An additional complication is the potential renaming of input data
column names in the Nonmem $INPUT section.
NMscanData by default (but optionally) follows the column
names as read by Nonmem.
This way of reading the output and input data is fully compatible with most other of the great R packages for reading data from Nonmem.
In most cases, the steps above are not too hard to do. But with the
large degree of flexibility Nonmem offers, the code will likely have to
be adjusted between models. The implementation in NMdata
works for the vast majority of models and aims at preventing and
checking for as many caveats as possible. It is fast too.
Default argument values can be configured depending on your setup (data standards, directory structure and other preferences).
Like the rest of NMdata, this functionality assumes as
little as possible about how you work. It assumes nothing about the
Nonmem model itself and as little as possible about the organization of
data and file paths/names. This makes it powerful for meta analyses, for
reading a model developed by someone else - or one written by ourselves
when we used to do things slightly differently. It will work out of the
box in the vast majority of cases.
We start by attaching NMdata. Also, I use
data.tablefor a few post-processing steps. You can just as
well use base R or dplyr if you prefer. Then
ggplot2.
library(NMdata)
#> NMdata 0.2.5.903. Browse NMdata documentation at
#> https://NMautoverse.github.io/NMdata/
## not necessary for NMdata to run, but we use thse in the examples
library(data.table)
#>
#> Attaching package: 'data.table'
#> The following object is masked from 'package:base':
#>
#> %notin%
library(ggplot2)
theme_set(theme_bw()+theme(legend.position="bottom"))For the examples we will be using files that are available in the
NMdata package. To type a little less, we use this shortcut
function:
file.NMdata <- function(...) system.file(file.path("examples/nonmem",...), package="NMdata")Note on file names and directory structures
Depending on your Nonmem setup, habits and preferences, you may name
your control streams and list files differently than this vignette.
Here, we use the NMdata default which is .mod
and .lst. You can easily configure NMdata to
match your preferences. See the FAQ
for how. So for now, rest assured that this is easy to adjust and read
on.
Get started - the basics
Try NMscanData on a control stream or a list file:
res1 <- NMscanData(file.NMdata("xgxr018.lst"))
#> Input and output data were searched for candidate unique row identifiers. None
#> found. To skip this check, please use merge.by.row=TRUE or merge.by.row=FALSE.
#> Model: xgxr018
#> Number of rows, columns and distinct ID's
#> N's by source table, shown as used/available:
#> file rows columns IDs
#> xgxr018_res.txt (output) 905/905 6/6 150/150
#> xgxr018_res_vols.txt (output) 905/905 3/7 150/150
#> xgxr018_res_fo.txt (output) 150/150 1/2 150/150
#> xgxr4.rds (input) 905/1502 21/23 150/150
#> (result) 905 31+2 150
#> Input and output data combined by translation of
#> Nonmem data filters.
#> Distribution of rows on event types
#> Shown for output tables and result:
#> EVID CMT output result
#> 0 2 755 755
#> 1 1 150 150
#> All All 905 905NMscanData tells that it has read a model called
xgxr018 and how output and input data were combined. We
shall see how these properties can be modified in a bit. Then follows an
overview of how much data is used from the data files that were read. It
used
- one output data file (based on the
$TABLEsection(s) in the.lstfile) from which it used all 905 rows and all 15 column, totaling 150 different values ofID. - the input file, but only 905 out of 1502 rows and 22 out of 23 columns. Input data did not contain any ID’s that weren’t used.
In the resulting data, 755 out of the 905 rows are
EVID==0, the remaining 150 rows are
EVID==1.
Let’s take a quick look at key properties of the data that was
returned. It’s a data.frame with the additional
NMdata class (for now, we just use it as a
data.frame).
The data used for the example is a PK single ascending dose data set, great thanks to the xgxr package authors.
The obtained dataset contains both model predictions (i.e. from
output tables) and a character variable, trtact (i.e. from
input data). To the .lst (output control stream) file path
was supplied by us.
head(res1,n=2)
#> ID NOMTIME TIME EVID CMT AMT DV FLAG STUDY KA Q PRED RES WRES V2
#> 1 31 0 0 1 1 3 0 0 1 0.18123 10732 0 0 0 0.042
#> 2 32 0 0 1 1 3 0 0 1 0.18123 10732 0 0 0 0.042
#> V3 BLQ CYCLE DOSE PART PROFDAY PROFTIME WEIGHTB EFF0 CL EVENTU
#> 1 0.1786 0 1 3 1 1 0 87.031 56.461 0.7248126 mg
#> 2 0.1786 0 1 3 1 1 0 100.620 45.096 0.7248126 mg
#> NAME TIMEUNIT TRTACT flag trtact model nmout
#> 1 Dosing Hours 3 mg Dosing 3 mg xgxr018 TRUE
#> 2 Dosing Hours 3 mg Dosing 3 mg xgxr018 TRUEYou may have noticed that when reading the model, we were told that
37 columns were read while 39 columns are found in the result. The
reason is the last two columns added by NMscanData called
model and nmout. model obviously
contains the name of the model which is by default derived from the list
file name. See later in the “Recover rows” section what
nmout represents.
What will NMscanData return?
Column in output data can overlap, and data can be available in both
output and input data. The following main principles are followed by
NMscanData:
- Priority of data
- Output data prevails over input data
- Row-specific output data is preferred over ID-level
(
FIRSTONLYorLASTONLY) tables - Output tables are prioritized by their order of appearance (order of $TABLE sections)
- The primary aim is to return the output data. If input and output cannot be meaningfully combined (very rare), output will be returned.
- Properties of returned data if input data used
(
use.input=TRUE)- Input data column names will be default be returned as defined in
the
$INPUTsection in Nonmem. - Columns that are dropped in Nonmem (
DROPorSKIP) are included byNMscanData. - Columns that are not included in
$INPUTare named as in the input data file. - If rows are being recovered from input data (the
recover.rowsargument), no information from output is merged onto these rows.
- Input data column names will be default be returned as defined in
the
Once you have data from NMscanData, NMinfo
can be used to browse meta information on what data was combined and how
that was done.
Use a unique row identifier
Above, we were told that “Input and output data combined by
translation of Nonmem data filters (not recommended).” Because of the
very commonly used ACCEPT and IGNORE
statements in Nonmem $DATA sections, the rows in output
tables are often a subset of the input data rows. If no other
information is available, NMscanData reads and interprets
the ACCEPT or IGNORE statements and applies
them to the input data before combining with the output data.
A more robust approach is using a unique row identifier in both input
data and output data. NMscanData can use this for merging
the data. This means that the ACCEPT or IGNORE
are not interpreted at all. Even though NMscanData should
work even without, it is always recommended to always include a unique
row identifier in both input and output tables (in fact, we just need it
in one full-length output table).
The following model happens to have such a unique row identifier in
the column called ROW. The default NMscanData
behavior is to use the row identifier if it can find it. The name of the
column with the row identifier can be supplied using the
col.row argument (and the default can be changed using the
NMdataConf function). The default is to look for
ROW.
All features shown below will work whether you supply
col.row or not. We use col.row because it is
more robust and because it allows us to easily trace a row in the
analysis back to the source data. We are now told that the data was
merged by ROW - that’s better.
res1.tbl <- NMscanData(file.NMdata("xgxr003.lst"),as.fun=tibble::as_tibble)
#> Model: xgxr003
#> Number of rows, columns and distinct ID's
#> N's by source table, shown as used/available:
#> file rows columns IDs
#> xgxr003_res.txt (output) 905/905 7/7 150/150
#> xgxr003_res_vols.txt (output) 905/905 3/7 150/150
#> xgxr003_res_fo.txt (output) 150/150 1/2 150/150
#> xgxr1.csv (input) 905/1502 21/24 150/150
#> (result) 905 32+2 150
#> Input and output data merged by: ROW
#> Distribution of rows on event types
#> Shown for output tables and result:
#> EVID CMT output result
#> 0 2 755 755
#> 1 1 150 150
#> All All 905 905Get your preferred data class back from NMscanData
When reading res1.tbl, we also added the
as.fun argument. the “as.” refers to
as_tibble, as.data.frame,
as.data.table etc. - a function applied to the data before
it’s returned by NMscanData (or any other
NMdata function). So now we have a tibble:
class(res1.tbl)
#> [1] "NMdata" "tbl_df" "tbl" "data.frame"I happen to be a data.table user so I am more
comfortable working that way. Instead of using the as.fun
all the time, we will change the default behavior using the
NMdataConf function. Because NMdata is
implemented in data.table we don’t need to pass the
data.table::as.data.table function but we can (better) use
the string "data.table" (again, data.table is
the exception - for anything else, please pass a function):
NMdataConf(as.fun="data.table")Notice, NMdataConf will set the default value for all
NMdata functions that use that argument. So when setting
as.fun this way, we will get the desired class returned
from all data generating NMdata functions.
We don’t want the same information about the dimensions repeated, so
we use the quiet argument this time.
res1.dt <- NMscanData(file.NMdata("xgxr003.lst"),quiet=TRUE)As expected we got a data.table this time:
class(res1.dt)
#> [1] "NMdata" "data.table" "data.frame"Browse the metadata
An NMdata object returned by NMscanData
comes with meta information about when and how what was read, and how
the data was combined. The NMinfo function browses this
information, and three options are available. It provides three sections
of meta data:
“details”: A list including the function call, what options were effective (if input was included, rows recovered, if data was merged by a row identifier or combined by filters etc).
“tables”: Overview of the tables that were read and combined by
NMscanDataand properties of the different tables.“columns”: Information on the columns that were treated by
NMscanData(see example below).
The following shows the “columns” information as example. Remember,
we are still getting a data.table because we used
NMdataConf to change the configuration. We use the
data.table print function to only look at first and last
ten rows.
print(NMinfo(res1,info="columns"),nrows=20,topn=10)
#> variable file source level COLNUM
#> <char> <char> <char> <char> <int>
#> 1: ID xgxr018_res_vols.txt output row 1
#> 2: NOMTIME xgxr4.rds input row 2
#> 3: TIME xgxr4.rds input row 3
#> 4: EVID xgxr4.rds input row 4
#> 5: CMT xgxr4.rds input row 5
#> 6: AMT xgxr4.rds input row 6
#> 7: DV xgxr018_res.txt output row 7
#> 8: FLAG xgxr4.rds input row 8
#> 9: STUDY xgxr4.rds input row 9
#> 10: KA xgxr018_res.txt output row 10
#> ---
#> 31: trtact xgxr4.rds input row 31
#> 32: model <NA> NMscanData model 32
#> 33: nmout <NA> NMscanData row 33
#> 34: DV xgxr018_res_vols.txt output row NA
#> 35: PRED xgxr018_res_vols.txt output row NA
#> 36: RES xgxr018_res_vols.txt output row NA
#> 37: WRES xgxr018_res_vols.txt output row NA
#> 38: ID xgxr4.rds input row NA
#> 39: DV xgxr4.rds input row NA
#> 40: ID xgxr018_res_fo.txt output id NAThe column names are sorted by the order in the resulting dataset,
the order given by the COLNUM column. The variables in the
bottom that have COLNUM==NA were redundant when combining
the data (the same columns were included from other sources). The file
names and their source (input/output) and a “level” are given. “level”
is the information level of the source. Input data and full-length
output tables are “row” level, a firstonly or lastonly table is
id-level. And then there is the model column added by
NMscanData which is obviously model-level.
nmout is the other column added by NMscanData
and both model and nmout have NA
file and NMscanData as source.
More options and features
Let’s have a quick look at the data we got back. The following is
done with data.table. The comments in the code should make
it clear what happens if you are not familiar with
data.table. You can do this with base::tapply,
stats::aggregate, a combination of
dplyr::group_by and dplyr::summarize, or
whatever you prefer.
gmPRED is calculated for sample times only and
represents the geometric mean of population prediction
(PRED) by dose and nominal time.
## trtact is a character. Make it a factor with levels ordered by
## numerical dose level. The := is a data.table assignment within
## res3. In dplyr, you could use mutate.
res1.dt[,trtact:=reorder(trtact,DOSE)]
## Derive geometric mean pop predictions by treatment and nominal
## sample time. In dplyr, use group_by, summarize, and ifelse?
res1.dt[EVID==0,gmPRED:=exp(mean(log(PRED))),
by=.(trtact,NOMTIME)]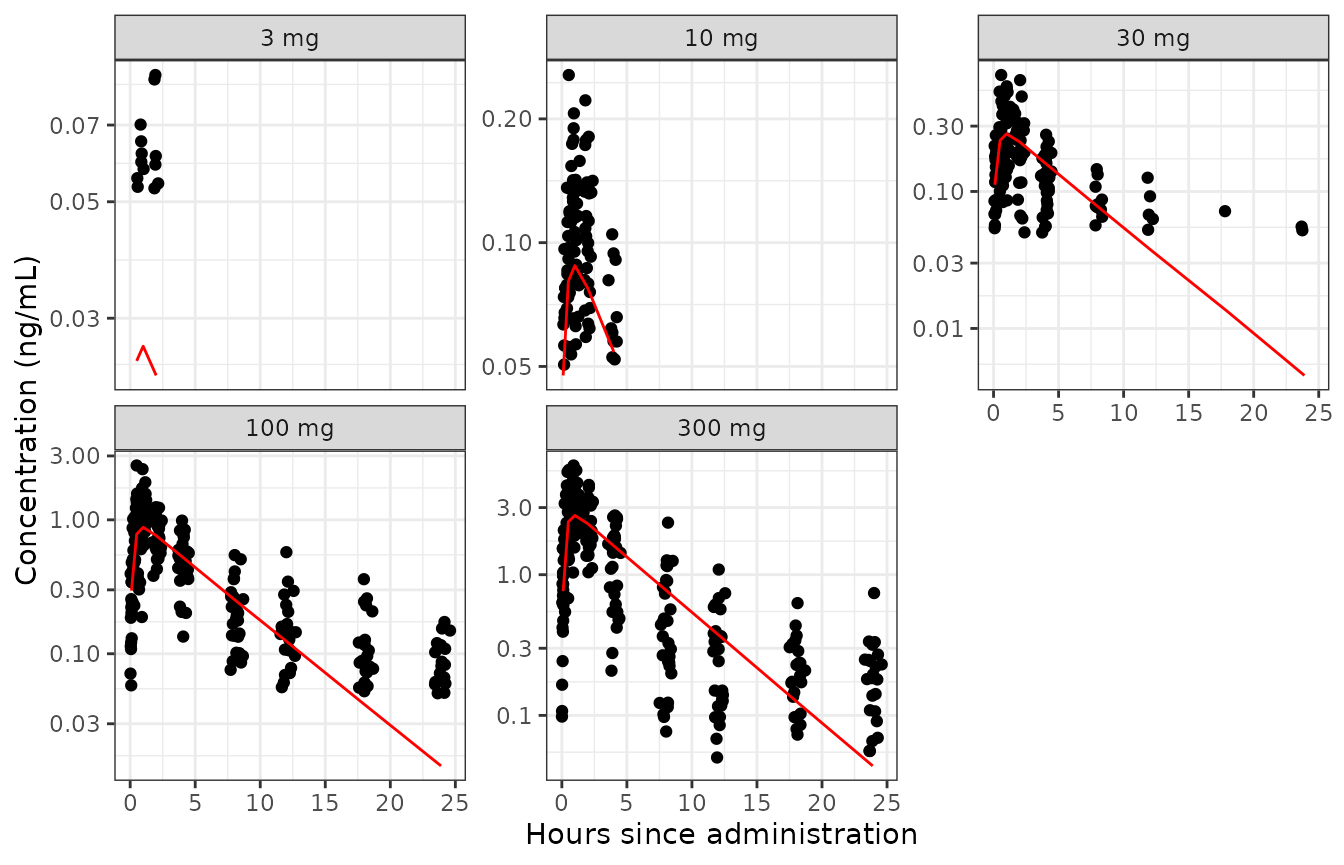
Notice, how little data is shown on the small doses. Remember, only
905 of the 1502 rows in the input data were used? Most of the rows
excluded in the analysis are so due to observation being below the
quantification limit (BLQ). The next section shows how to recover all
the input data rows with NMscanData.
Recover rows
We may want to include the input data that was ignored by Nonmem. Use
recover.rows=TRUE to include all rows from input data.
res2 <- NMscanData(file.NMdata("xgxr014.lst"),recover.rows=TRUE)
#> Model: xgxr014
#> Number of rows, columns and distinct ID's
#> N's by source table, shown as used/available:
#> file rows columns IDs
#> xgxr014_res.txt (output) 905/905 12/12 150/150
#> xgxr2.rds (input) 1502/1502 22/24 150/150
#> (result) 1502 34+2 150
#> Input and output data merged by: ROW
#> Distribution of rows on event types
#> Shown for output tables and result:
#> EVID CMT input-only output result
#> 0 1 2 0 2
#> 0 2 595 755 1350
#> 1 1 0 150 150
#> All All 597 905 1502Besides the model column holding the model name,
NMscanData creates one other column by default.
nmout is a boolean column created by
NMscanData expressing whether each row was in the output
data (nmout==TRUE) or they were recovered from the input
data (nmout==FALSE).
We recognize these numbers from the message from
NMscanData - the number of rows in output (905) and number
of rows from input only (597). Since we changed the default value of
as.fun with NMdataConf, res2 is a
data.table.
res2[,.N,by=nmout]
#> nmout N
#> <lgcl> <int>
#> 1: TRUE 905
#> 2: FALSE 597We make use of the nmout column to only calculate
gmPRED for observations (EVID==0) processed by
Nonmem.
## add geometric mean pop predictions by treatment and nominal sample
## time. Only use sample records.
res2[EVID==0&nmout==TRUE,
gmPRED:=exp(mean(log(PRED))),
by=.(trtact,NOMTIME)]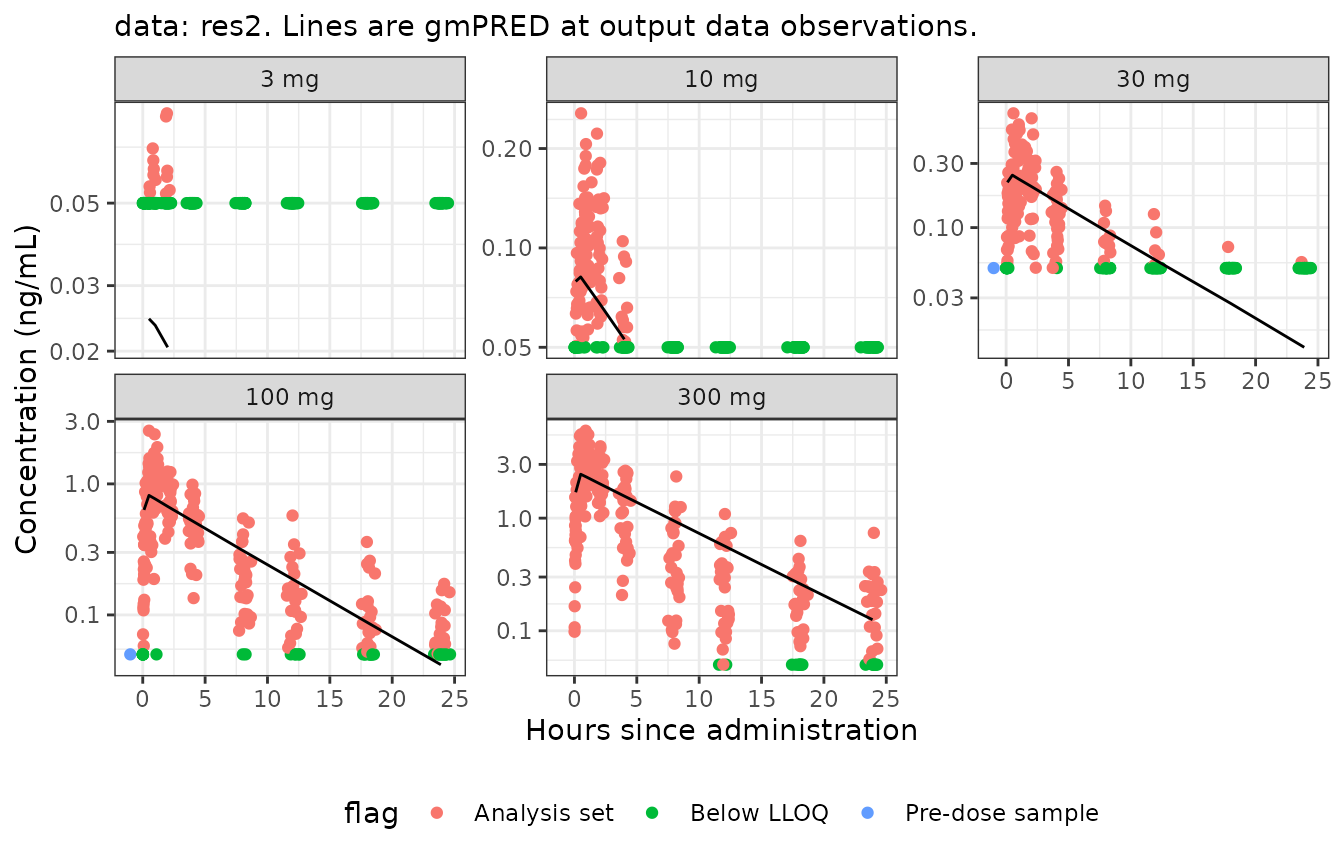
Obviously, we were lucky that meaningful values were assigned to
DV for the BLQ and pre-dose samples in input data, so we in
this case could easily plot all the data.
Combine multiple models
NMscanData by default adds a column called
model for convenience when working with multiple models.
You can specify both column name (which is by model
default) and model name (contents of that column) as arguments in
NMscanData. Using NMdataConf, You can also
configure the default column name and the function that generates the
model name.
The default is to derive the model name from the lst
file name (say,
xgxr001.lst becomes xgxr001). In the
following we use this to compare population predictions from two
different models. We read them again just to show the use of the
argument to name the models ourselves. Remember, we configure
NMdata’s as.fun option so we are working with
data.table and we easily stack with rbind
(rbind.data.table) filling in NA’s. We add a
couple of options to specify how input and output data are to be
combined.
NMdataConf(as.fun="data.table", ## already set above, repeated for completeness
col.row="ROW", ## This is default, included for completeness
merge.by.row=TRUE ## Require input and output data to be combined by merge
)
res1.m <- NMscanData(system.file("examples/nonmem/xgxr001.lst", package="NMdata"),
quiet=TRUE)
## using a custom modelname for this model
res2.m <- NMscanData(system.file("examples/nonmem/xgxr014.lst", package="NMdata"),
modelname="One compartment",
quiet=TRUE)
## notice fill is an option to rbind with data.table (like bind_rows in dplyr)
res.mult <- rbind(res1.m,res2.m,fill=T)
## Notice, the NMdata class disappeared
class(res.mult)
#> [1] "data.table" "data.frame"
res.mult[EVID==0&nmout==TRUE,
gmPRED:=exp(mean(log(PRED))),
by=.(model,trtact,NOMTIME)]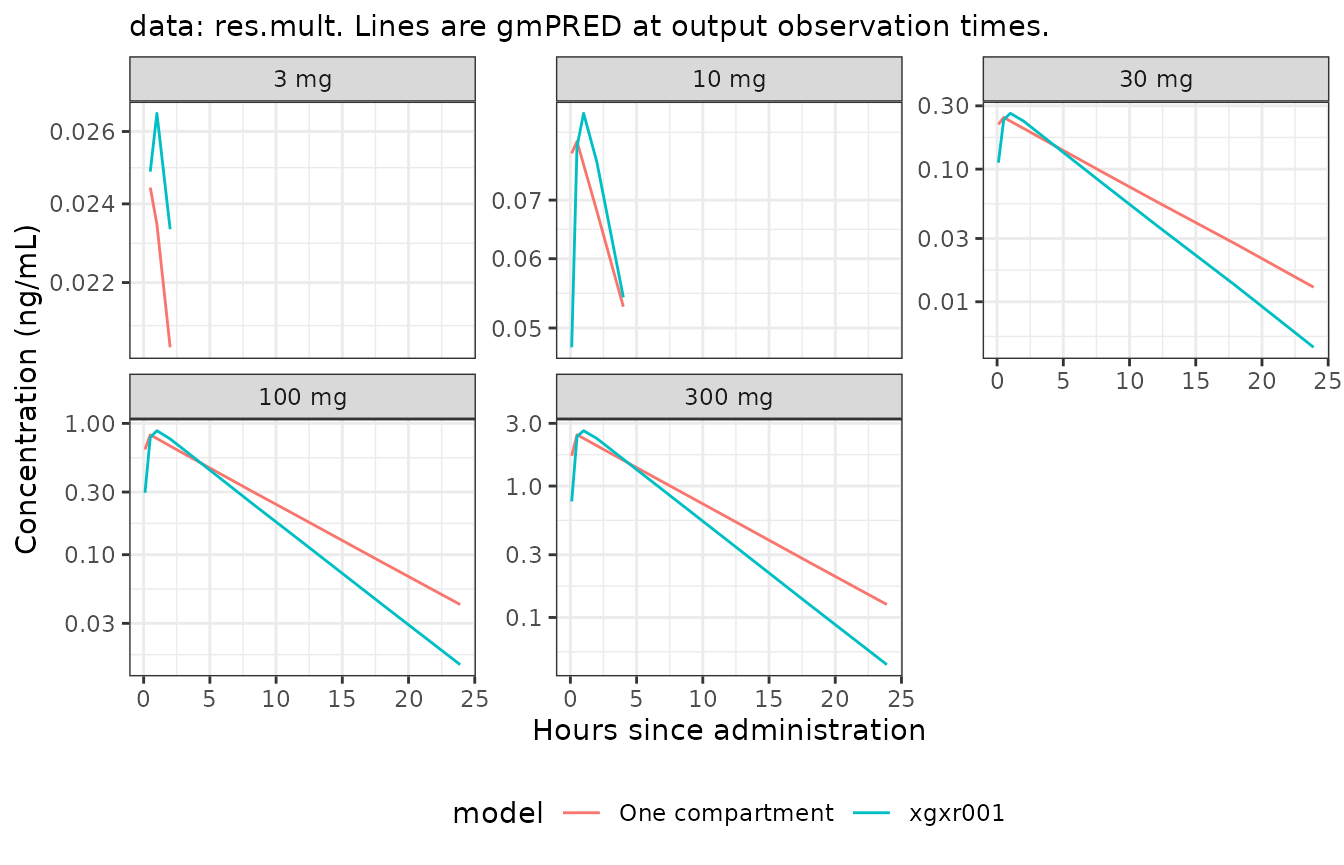
In this, we specifically wanted to rename one model for illustration
of the modelname argument. We can pass a function to
customize how NMscanData derives it from the list file
path. This one skips the characters and leading zeros, so we just get an
integer. We could pass use the modelname argument in
NMdata but why not changed the default instead?
namefun <- function(path) sub("^[[:alpha:]0]+","",fnExtension(basename(path),""))
NMdataConf(modelname=namefun)
res1.m <- NMscanData(system.file("examples/nonmem/xgxr001.lst", package="NMdata"),
quiet=TRUE)
res2.m <- NMscanData(system.file("examples/nonmem/xgxr014.lst", package="NMdata"),
quiet=TRUE)
## notice fill is an option to rbind with data.table (like bind_rows in dplyr)
res.mult <- rbind(res1.m,res2.m,fill=T)
res.mult[,.N,by=model]
#> model N
#> <char> <int>
#> 1: 1 905
#> 2: 14 905
## resetting default
NMdataConf(modelname=NULL)NMdataConf can be used to change a lot of the default
behaviour of the functions in NMdata so it fits in with
your current setup and preferred work flow.
Preserve all input data properties - use rds
Return to the example above creating the dataset res22.
Notice in the list of tables in the message from
NMscanData, that input data was a .rds file.
This is why we could sort the plots correctly on the dose level without
reordering the factor levels first.
res2[,class(trtact)]
#> [1] "factor"
res2[,levels(trtact)]
#> [1] "Placebo" "3 mg" "10 mg" "30 mg" "100 mg" "300 mg"If the argument use.rds is TRUE,
NMscanData will look for an rds file next to the input data
file (which is a delimited text file) the exact same name as the text
file except the extension must be .rds rather than say
.csv (for Nonmem and NMscanData, the extension
of the delimited text file doesn’t matter). If it finds the
rds file, this will be used instead. No checks are done of
whether the contents are similar in any way to the delimited text file
which is ignored in this case.
There are three advantages of using rds files:
- All attributes are kept. This includes column classes and factor levels.
- Reading speed may be improved (NMdata uses
freadfromdata.tablewhich is extremely fast for delimited files so in many cases this difference can be small). - File sizes are greatly reduced from text to
rds. This can be a big advantage if you are transferring files or reading over a network connection.NMdatais generally very fast (thanks todata.table) so file/network access (I/O) is likely to be the main bottleneck.
If you write Nonmem datasets with the
NMdata::NMwriteData, you can get an rds file
automatically, exactly where NMscanData will look for it.
Preparing datasets using NMdata is described in this
vignette.
You probably want to use NMdataConf to change the
default behavior if you don’t want to use rds files.
Reading data without automatically combining it - the
NMscaData building blocks
Each of the steps involved in reading and combining the data from a model run can be done separately.
The lst file was scanned for output tables, and they
were all read (including interpreting the possible
firstonly option). The input data has been used based on
the $DATA and $INPUT sections of the control
stream. The key steps in this process are available as independent
functions.
NMreadTab: Read an Nonmem output table based on the path to the output table file.NMscanTables: Read all output data files defined in a Nonmem run. Return a list of tables (as data.frames or data.tables).NMtransInput: Read input data based on a Nonmem file. Data will be processed and named like the Nonmem model.ACCEPTandIGNOREfilters can be applied as well. There are a few limitations to this functionality at this point. More about them below.
What should I do for my models to be compatible with NMscanData?
The answer to this should be as close to “nothing” as possible -
that’s more or less the aim of the function. You just have to make sure
that the information that you need is present in input data and output
data. No need to output information that is unchanged from input, but
make sure to output what you need (like IPRED,
CWRES, CL, ETA1 etc which cannot
be found in input). Some of these values can be found from other files
generated by Nonmem but notice: NMscanData uses only input
and output data.
It is recommended to always use a unique row identifier in both input and output data. This is the most robust way to merge back with input data. In firstonly tables, include the subject ID. Again, everything will most likely work even if you don’t, I personally don’t like relying on “most likely” when I can just as well have robustness.
Limitations
Even if there are a few limitations to what models
NMscanData can handle, there is a good chance you will
never run into any of them, as they are mostly quite rare. If you do,
reach out to me, and we’ll figure it out.
Input data file must exist and be unmodified since model run
If merging with input data, the input data must be available as was
when the model was run. If you want to avoid this potential issue,
Nonmem can be run in a wrapper script that either copies the input data,
or runs NMscanData and saves the output in a compressed
file format (like rds or zip).
Not all data filter statements implemented
Nested ACCEPT and IGNORE statements are not
supported at this point. The resulting number of rows after applying
filters is checked against row-level output table dimensions (if any
available). In other words, you have to be unlucky to run into trouble
without an error. But it is always recommended to use a unique row
identifier in both input and output tables in order to avoid relying on
interpretation of Nonmem code.
The RECORDS and NULL options in
$DATA are not implemented. If using RECORDS,
please use the col.row option to merge by a unique row
identifier.
Character time variables not interpreted
Nonmem supports a clocktime input format for a column called TIME in
input data. Based on a day counter and a character (“00:00”) clock
format, Nonmem (or rather, NM-TRAN) can calculate the
individual time since first record. This behaviour is not mimicked by
NMscanData, and the only ways to get TIME in this case are to either
include it in an output TABLE or to code the translation
yourself after calling NMscanData. Of course, this is on
the todo list.
Some TABLE options not supported
For now, only output tables returning either all rows or one row per
subject can be merged with input. Tables written with options like
FIRSTLASTONLY (two rows per subject) and
OBSONLY are disregarded with a warning (you can read them
with NMscanTables). LASTONLY is treated like
FIRSTONLY, i.e. as ID-level information if not available
elsewhere.
Summary
In this vignette you should have learned to
-
NMscanDatacan automatically read and combine all output and input data, only based on the path to the list (.lst) file- Output data is prioritized over input data
- Switch between combining output and input data by mimicking the
Nonmem data filters (IGNORE/ACCEPT) and merging by a row identifier
-
merge.by.rowis the argument of interest
-
- Configure
NMdatato return your favorite data class-
NMdataConf(as.fun="data.table")fordata.table -
NMdataConf(as.fun=tibble::as_tibble)for tibbles (tbl)
-
- Look up meta data on input and output tables, how they were
combined, and results of checks performed by
NMscanData- Use
NMinfoon the result coming out ofNMscanData
- Use
- Include input data rows that were not processed by Nonmem
recover.rows=TRUE
- Combining such data sets for of a multiple models
- By default, the column called
modelwill hold the model name which you can use when combining (rbind) multiple model data sets - Use the
modelnameoption to change the model name or how the model name is derived from the list file path.
- By default, the column called
- Use an
rdsfile to preserve all input data-
NMdata::NMwriteDatawrites thisrdsfile by default
-
You should have seen that NMscanData have very little
limitations in what Nonmem models it can read. You should not have to
change anything in the way you work to make use of
NMscanData.